Musings on “Composable Infrastructure”
This tweet (http://bit.ly/1NZJxUQ) from @CiscoServerGeek referenced a Cisco blog post on “Composable Infrastructure”. While the concept has the usual “independent market analyst” marketing wrappings to it, the technology implications are actually very intriguing — at least to me. Plus, he offered up a challenge so I couldn’t resist the gedankenexperiment (http://bit.ly/1SPbC38). I’ll explain.
A Quick Recap
The term “Composable Infrastructure” references a trend embodied in the development in the Cisco UCS product line. Namely, the UCS continues to expand the abstraction of the physical server itself - beginning with its identity when UCS was introduced - so that the logical entity we call server can leverage different physical server components throughout its lifetime. Today, you can see this abstraction most plainly in the service profile technology - namely, a logical server (unique set of UUID, MAC, WWPN, etc.) can live on any similar physical equipment.
The blog post series at Cisco (http://bit.ly/1HwJTD1) illustrates expansion of the “disaggregation” of physical resources to include storage (today in the UCS M-series). Today, the M-series chassis “owns” the physical storage and networking resources. The blade cartridges are “just” CPU and memory components that plug into the chassis. To create the logical server entity, a UCS service profile leverages storage profiles, virtual adapters extended to the cartridge (a natural progression of VM-FEX (http://bit.ly/1MbCU17) IMO), and System Link Technology (http://bit.ly/1QtQ10K) to bring it all back together.
The Challenge
The point of this post - the suggestion was made to “just imagine further right”. I’ve included the figure below from the blog post to aid the hypothesizing:
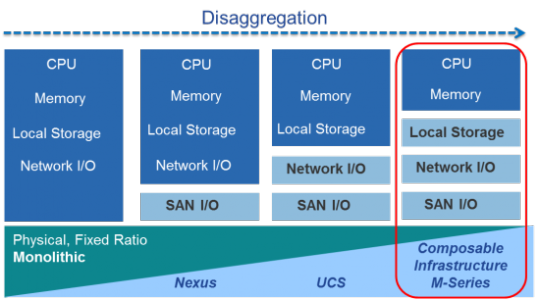
So, what would that look like? The suggestion from the tweet would lead us to believe the next step is the separation of the CPU and memory. Today, there is a serious challenge to that trend and it’s buried deep inside the Intel processor itself — the memory controller! Intel re-engineered its processor so that it could have better memory performance overall with QPI links even if it was no longer uniformly distributed (NUMA).
Leaks of the Skylake processor (http://bit.ly/20LxaTg) suggest more of the same at faster speeds - with some interesting additions (100Gbps OmniPath [http://intel.ly/1L9z4Sc] link on each socket). On the surface, though, nothing that screams radically different design of the memory architecture. So, clearly, if anything is to continue the disaggregation trend, it will have to be some special technology that Cisco develops (like System Link).
Disaggregating the Memory?!
“Not so fast, my friend”— Cisco is no stranger to developing ASICs, as they are extremely fond of emphasizing. They have developed some nice ASICs around the memory architecture on servers, e.g. the “Extended Memory Technology” in M1 and M2 blades (http://bit.ly/1NJfmDb). That ASIC sits in front of the memory channels coming out of the CPU and multiplexes multiple DIMMs to appear as a single, larger DIMM.
But, what if an ASIC (EMT NG or EMT 3.0) can be built in front of some (or all) memory DIMMs in the back of an M-series chassis and have crosslinks to some (or all) of the processors? You could then physically aggregate the memory banks and thus free the processor cartridges up to be smaller. From a thermal design perspective, you could possibly architect the chassis to increase cooling efficiency even more by localizing resources into different aggregation zones — e.g. CPU zone vs Disk zone vs Memory zone.
More importantly, you could get the benefit of “investment protection” — yes, another fond emphasis of Cisco. Since the ASIC would essentially be a bridge between the CPU and DIMMs, you might even be able to reuse DIMMs across the Tock/Tick boundary and merely swap out CPUs. You get that today between the Tick and Tock boundary because (IIRC) the socket form factor doesn’t change (in recent micro-architectures) thus permitting a Sandy Bridge to Ivy Bridge CPU swap out without issue.
I can definitely see this disaggregation operating at the socket level. Socket 5 gets 32GB of RAM, Socket 7 gets 8GB of RAM. I don’t easily see this getting down into the sub-socket or core level without a lot of help from Intel.
Interesting concept. What’s the point?
That being said, do you have to get to partitioning the socket itself?
In the coming age of containers and micro-services, why do I need a hypervisor? Especially at the cost of thousands of dollars per socket? Sure, there’s OpenStack and KVM to help on the the cost, but I still have the hypervisor layer to architect and manage in an infrastructure stack that always seems to be getting deeper and deeper.
Why can’t the service profile play the role of the VM construct?
If I can get a generic pool of CPU, RAM, and storage resources (as I’ve hypothesized above), I could have an 64GB socket with 16-20 cores and SAN storage running my DB. In the same hardware pool, I could also have an 8GB socket with 16-20 cores for my Linux container engine OS (name your favorite one here).
If we are really drinking the strong beverages, why not be able to mix processors connected into the same, shared memory pool? 4 Intel E3v2s for container engine, 2 E5v3s for DBs, etc.
All with the UCS service profile.
And no hypervisor required.
Hmmm…