Efficient Resource Use Takes Interesting Turn at Scale
The first couple of sections set the backdrop for why the technology by DriveScale is really interesting. If you want to skip it, for shame on you (but jump to Composable Big Data Platform section).
Background
Throughout the history of computing, there has always been the constant back and forth between producers and consumers of computational resources. Build a resource with more horsepower and users will run more workloads or run bigger workloads. We’ve seen this trend play out in scientific computing and, in many respects, the enterprise.
In the enterprise, we have, historically, been plagued with large numbers of business critical, resource-light applications with conflicting software dependencies - end result of course was a large data center full of underutilized servers. The enterprise drove efficiencies by virtualization of services/applications, consolidation of databases onto fewer servers, and leveraging of dedicated, optimized NAS appliances - among other technologies.
In scientific computing, we come to computing from the other side of the coin! Generally, there have not been enough servers to get the work done in a timely fashion so we throw more servers at it. Sometimes that derives from the complex nature of the calculation, other times it’s because the data sets are somewhat large (<10TB today). End result of course were Linux HPC clusters that aggregate large numbers of servers, using scheduling software to efficient place the workloads.
Generally speaking, though, as Moore’s Law has drive computational horsepower, eventually servers end up having more and more processor cycles idle because the other critical resources (networking and storage) have not had been able to keep the pace…
Enter Big Data
The last 3-5 years have seen a huge explosion of data growth - in both enterprise and scientific research. The rates have far exceeded what compute and networking can handle in order to effectively process it all. Thus, it is a very interesting development to me that both enterprise and scientific computing have both reach big data scales roughly at the same time.
Even more interesting that the lines between enterprise and scientific computing are blurring rapidly - both in mutual dependency (for example, medicine and hospitals) and in required skill sets (statistic analysis/machine learning and … well, everything!). That, though, is a discussion for another time.
The primary notion behind big data is that the data sets have become too large to efficiently move to the compute resources for analysis. Additionally, those data sets are analyzed repeatedly - which would normally suggest a caching approach except for the scale involved - so you would have to build large, cost-prohibitive networks to support the old model.
So, in general, a new model arose for big data: move compute to the storage appliance. Generally speaking, throw 50 or so drives in a multi-socket server chassis and use novel techniques to distribute the analysis to the compute fronting those drives. Seems simple and problem solved, right?
Footnote: For those who want a deeper backgroung, head over to Wikipedia for Big Data, Apache Hadoop, and Apache Spark.
Big Data parallels the HPC story
As with HPC Linux clusters in the 2000s, big data has experienced a similar adoption pattern. Initially, we have large data sets that are CPU-bound. We build a big data “cluster” tuned to that application, throw all of our data into it, and essentially dedicate a massive set of resources to a single problem.
As the framework shows value, more applications are adapted to the new paradigm - originally, this approach was used by Google for search engine results. Today, you can easily find big data solutions for system log analysis, medical record mining, and stock market analyses.
The important thing to note, though, is that each application has its own large data set and different ratio of computation to storage requirements. These infrastructure bundles can be sizable and expensive so how do we support each application? The answer, very early on was: a big data cluster for every application! (Cue the obligatory Oprah clip…)
Except… just because we have a new model does not mean the various advancements in compute, network, and storage are no longer relevant. Computational power is eventually going to surpass what you can store locally. Eventually, big data platforms are going to experience the same resource inefficiencies that fed into the virtualization movement in the enterprise and dynamic scheduling of scientific computing.
Furthermore, what if you are a service provider? Do you build dedicated big data clusters for each application a customer has? Or can you build a Big-Data-As-A-Service platform efficiently?
Composable Big Data Platform?
These are the sorts of problems that the folks at DriveScale are beginning to tackle. The team they’ve assembled, as my friend John White points out in his blog, has a strong pedigree in the IT industry. The fundamental approach they’ve adopted involves disaggregating the storage from the compute without introducing too high a performance penalty in doing so.
In the traditional approach, you must select among chassis and server platforms whose primary goal is to provide you with the best quantity of storage with the needed performance. Those platforms have to make trade-offs that limit the server configurations. HPe Apollo 4500s for example - you can get 68 drives with one server node but must sacrifice drive slots to get a second node. Both HPe and Cisco platforms limit the amount of memory available to your servers in the interest of physical foot print.
The DriveScale approach starts with standard off-the-shelf JBOD storage shelves that are fronted by the DriveScale controllers using 12Gbps SAS interconnects. The controllers are extremely efficient data movers, transfering bits between the JBOD drives and the mapped servers. The servers? Any server configuration to fit your computational need - Dell, Cisco, HPe, Supermicro - so long as it has 10GE capability. And, yes, like servers - your choice of 10GE switch (there’s an HCL too) to connect the 10GE servers to the 10GE DriveScale controllers.
Here’s what a typical rack looks like physically:
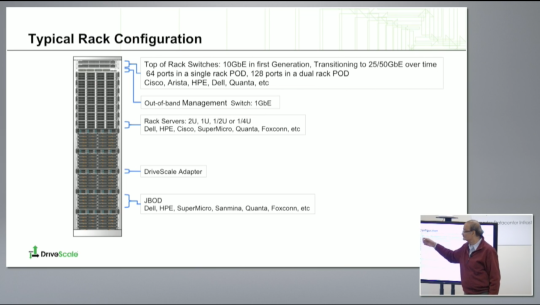
Logically, this is how it connects together within the rack:
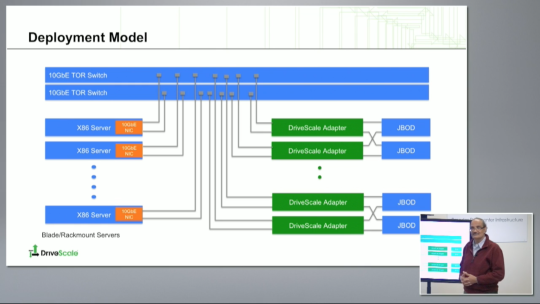
Drilling down into the magic hardware sauce, namely the DriveScale appliance and controllers - the 1RU appliance has four DriveScale controllers in it. Each controller has dual 20GE uplinks to your servers. A pair of those controllers attach to a single dual controller (SAS 12Gbps based) JBOD array. Here’s the logical drawing for that appliance:
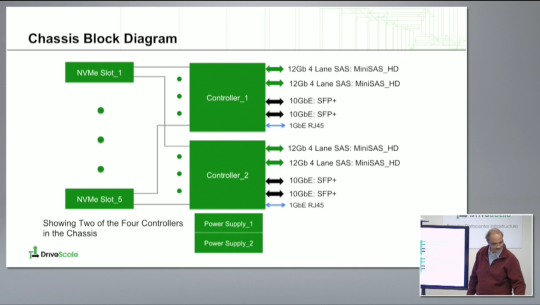
Note: the NVMe SSDs on the front are not quite available yet (Nov 2016).
Flexibility sacrificing performance?
If this reminds you of other architectures, it should. It’s not very different (in boxes and lines drawing) from NAS/SAN controller architectures. However, as opposed to those architectures, the data path for all the storage is not focused through a single pair of controllers. The platform scales horizontally, based on their presentation, to 16 controllers per rack. Additionally, the expansion shelves are not unique to the controller vendor - more about that below.
Concerned about the 10GE fabric for scaling out? There are a few details to calm your fears. First, you are sending all your traffic across a single, non-blocking Ethernet switch within the rack. There is no oversubscription between storage and server (by crossing your network core, e.g.). Second, there is nothing to stop you from going 25GE or 40GE in your server and network switching…
Which leads to the third “detail”, the roadmap. They are driving toward 25/40/100GE based architectures for their appliance. It wasn’t clear to me but 25GE is certainly real soon now but I wasn’t clear on when 40/100GE was arriving. On that note, you should check out their video presentations or the main page http://techfieldday.com/event/tfd12 for more information.
DriveScale is Software too!
Ultimately, the DriveScale approach is all about scaling out your capabilities using cost effective components. It very much follows the HPC cluster model of using commodity compute hardware (that meets your needs), using commodity storage hardware. Similarly to HPC, special middleware is needed to intelligently glue the components together to provide the ultimate services required. In HPC, that is both the job scheduler and the parallel filesystem
For DriveScale, the software not only provides the management layer to monitor hardware, map resources, etc., it manages distributing the load across the appliances, handling redundancy (presumably via erasure coding) if required, etc. Rather than try to reproduce the details, I will refer you to the 20-ish minute video on the capabilities and benefits of the software on the Tech Field Day YouTube channel. How they enable these capabilities is very interesting.
Wrap Up
One key component to these large environments that frequently gets overlooked is hardware life cycle management. In HPC, especially the large clusters at national laboratories, “upgrading” is rip and replace with a brand new resource (for good reason, by the way). In traditional big data platforms, the approach is the same - especially when it comes to HDFS. Operationally, HDFS doesn’t easily rebalance data so incrementally adding space is not a great or easy option - which is why the best practice is to fully populate all drives in a node.
DriveScale, on the other hand, by physically separating the server from storage, permits you to refresh the server components completely independent of the storage as well as refreshing the storage separately as well. The “bridging” function of the DriveScale hardware (SAS to Ethernet) and software (logical mapping of drive to server) permit this extremely valuable flexibility.
Another key component at this scale, supply chain! The DriveScale simply sells the appliances and the software. You are responsible for buying the storage (JBODs) and servers. Given the scale of compute and storage, the DriveScale folks (rightly) do not want to insert themselves into the supply chain - it’s not their expertise and the mechanics of SCM would easily dwarf the primary mission.
In my view - this is a very good thing! How many times do you have a great platform/product you need for your business but have to tough out a new set of management interfaces, different support mechanisms (and quality of service), etc. You get to choose my servers, my drives, and my network.
My perspective
While the technology is very fascinating to me, I am most excited by these points I made in the wrap up. As a infrastructure engineer, operational and lifecycle issues are really important. You can’t simply vMotion an application off one server in order to replace the server! When you have a critical application or service that many groups (or the entire business) rely on, you want to be able to maintain it, refresh it, and improve it without having to take it offline.
In my HPC past, I have used IBM GPFS (now call Spectrum Scale) to perform similar independent upgrades of storage appliances from the storage servers. So, even though my academic HPC life has been lived at “the small scale” (of 100+TBs and 2000 cores), I can easily appreciate the approach DriveScale is taking at much larger scales of storage.
Disclaimer
Please see my general disclaimer on all content I write on this blog. I saw the DriveScale presentations in person, as a delegate for Tech Field Day 12.